그록은 최근 인공지능 업계에서 가장 화제가 되는 모델 가운데 하나입니다. 특히 AI 체스 토너먼트 결승전에서의 돌발 변수와 패배 이슈가 알려지며, 그록의 한계와 가능성에 대한 논의가 뜨거워졌습니다. 이 글에서는 그록의 개요, 결승전 타임라인, 기술적 배경, 도전 과제, 그리고 향후 전망까지 객관적으로 정리합니다.
그록 개요
그록은 최신 딥러닝 기반 전략 엔진을 탑재한 AI 모델로, 복잡한 상태 평가와 빠른 의사결정을 강점으로 합니다. 체스·바둑 같은 완전정보 게임에서 높은 퍼포먼스를 보여 왔고, 데이터 효율을 높이는 전이 학습과 대규모 자기대국(self-play) 파이프라인을 결합해 성능을 끌어올렸다는 평가를 받습니다.
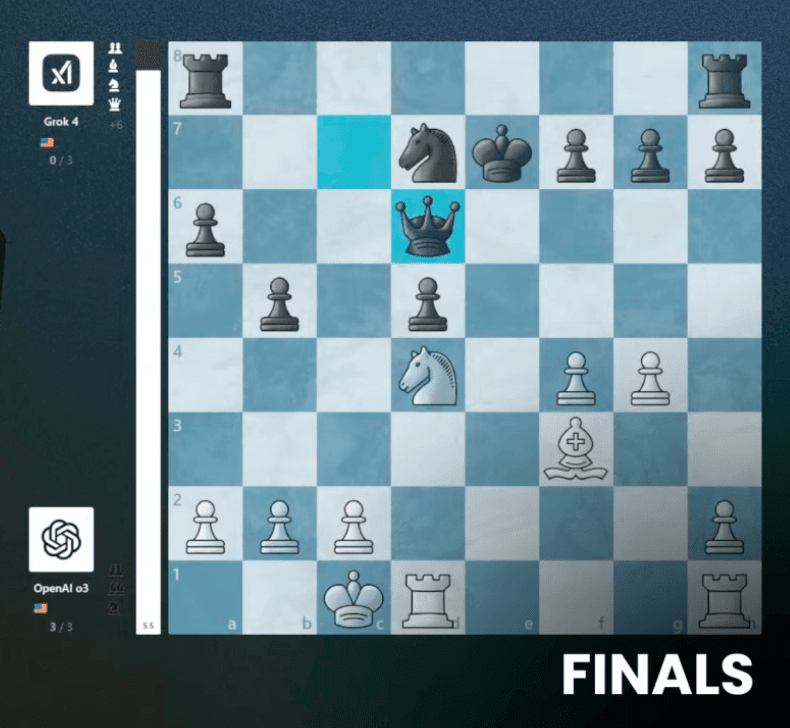
주요 사건과 타임라인
2023년 AI 체스 토너먼트에서 그록은 결승까지 진출하며 강력한 우승 후보로 거론되었습니다. 하지만 결승전 중반, 계산 트리 분기 선택에서 비정상적 흔들림이 나타났고, 연속적인 국면 평가 오류가 발생했습니다. 초반 리드를 지키지 못한 채 전략 붕괴로 패배했고, 이 장면은 “고성능 모델도 예외 상황에 취약할 수 있다”는 사실을 각인시켰습니다.
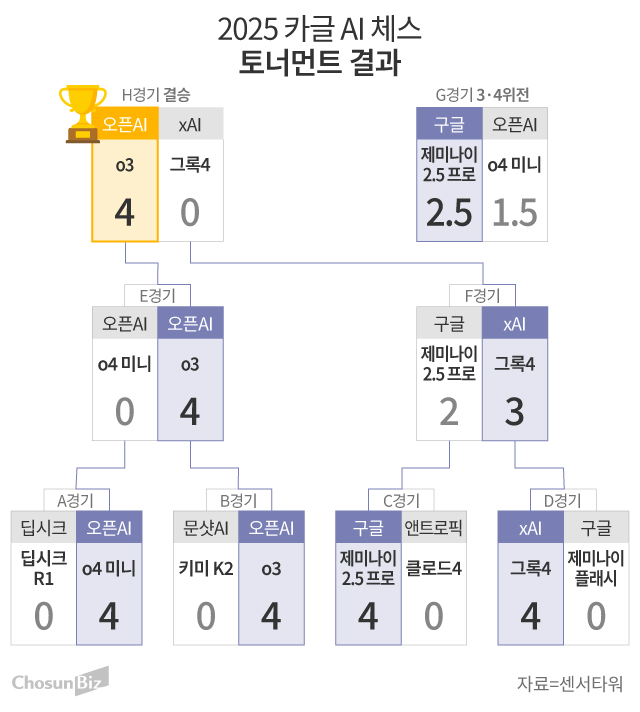
이벤트 상세 분석
리뷰에 따르면 그록은 초반 오프닝 준비도가 높았고, 미들게임 초입까지 기대 승률을 유지했습니다. 그러나 특정 변형에서 탐색 깊이 조절과 정책-가치 네트워크 간 신호 불일치가 생기며 ‘과신(Overconfidence)’ 성향을 보였습니다. 이로 인해 위험-보상 균형이 무너졌고, 엔드게임 진입 전에 돌이키기 힘든 손실이 누적되었습니다.
세부 내용 및 기술적 배경
그록의 학습 파이프라인은 전이 학습(다양한 기보·시뮬레이션 데이터)과 자기대국을 결합합니다. 정책 네트워크는 합리적인 후보군을 좁히고, 가치 네트워크는 각 국면의 승률을 예측합니다. 여기에 MCTS(몬테카를로 트리 탐색) 또는 유사 검색 전략을 활용해 탐색 효율을 최대화합니다.
그럼에도 결승전에서 드러난 취약점은 몇 가지 교훈을 줍니다. 첫째, 데이터 분포 밖(Out-of-Distribution) 상황에서 가치 함수가 불안정할 수 있습니다. 둘째, 하드웨어·스케줄링 요인(시간 제약·온디바이스 최적화)과 결합하면 탐색 깊이가 얕아질 수 있습니다. 셋째, 복합 잡음 환경에서 정책-가치 상호보완이 무너질 경우, 작은 오차가 연쇄적으로 확대됩니다.

기술적 도전 과제
- 불확실성 대응: 분포 밖 국면에 대한 캘리브레이션, 리스크 민감 정책 도입
- 전략 다양성: 동일 패턴 과적합을 피하기 위한 커리큘럼/도메인 랜덤화
- 안정성·회복력: 실시간 자기점검(Self-check)과 페일세이프 수 탐색
정리 및 앞으로의 전망
그록의 결승전 패배는 한계의 노출이자 개선의 출발점입니다. 데이터 증강과 탐색 정책 다변화, 불확실성 추정의 정교화가 이뤄지면, 유사 상황에서의 회복 탄력성은 충분히 높아질 수 있습니다. 장기적으로는 ‘인간과의 협업형 전략 보조’로 확장되며, 의사결정 품질을 끌어올리는 방향이 유력합니다.
덧붙여, AI 경쟁은 승패를 가르는 이벤트를 넘어 연구 커뮤니티 전체의 학습 기회입니다. 그록이 다음 버전에서 어떤 해법을 적용할지, 또 어떤 기준으로 안전성과 공정성을 강화할지 지켜볼 만합니다. 관련 맥락은 내부 가이드인 AI 윤리·안전 가이드에서 더 확인할 수 있습니다.
참고 자료
주: 본 정리는 공개 보도를 토대로 한 기술·이슈 분석이며, 세부 수치는 업데이트에 따라 변동될 수 있습니다.